Practical Issues in Policy Deployment
This chapter describes how the locomotion policy is deployed and validated on real hardware, and which practical issues mattered most during sim2real transfer.
1. Processor-in-the-loop validation
Before deploying to hardware, the locomotion stack is validated through the processor-in-the-loop path described in Understanding Your Simulation Environment. This section focuses on the deployment-specific validation that path enables.
2. Jitter and delay must be exercised before deployment
Motor timing on paper is not the same as motor timing in a running system. The deployment path therefore validates controller behavior under injected delay and jitter.
The motor emulator is used to insert randomized response timing so that the stack can be tested against:
- late motor responses
- race conditions in the control loop
- protocol parsing issues under load
- timing mismatch between sensor and control computation
This turns delay handling into an integration test rather than an assumption.
Representative injected delay was drawn over a range spanning approximately 0.4 ms to 2 ms, which was enough to expose timing assumptions in the firmware and policy loop before hardware tests.
3. CAN ordering mattered
One of the important deployment issues was the ordering of motor-state data on the CAN path.
Early behavior allowed requests to be issued in sequence while responses could arrive in different order. Even though this is logically acceptable at the communication layer, it created a control problem:
- the policy interpreted stale and reordered state as a real physical deviation
- corrective action was applied too aggressively
- the resulting impulses excited oscillations across the legs
The fix was to make the real IO sampling path behave more like the training environment by sampling actuators at the intended rate and waiting for the expected packet order.
The important lesson is that conceptual correctness at the communication layer is not sufficient. If the data arrives in a different temporal structure than the policy expects, the control loop can still fail.
4. Oscillation should be treated as a systems problem
Severe startup oscillation was not solved by adding more rewards. It was the result of two interacting causes:
- Underdamped policy behavior — the simulation KP/KD values produced underdamped dynamics, causing the policy (an MLP) to learn underdamped control behavior that it carried onto the real robot. The full failure chain is documented in Deep Dive: System Identification.
- Stale and reordered motor-state data — CAN packet ordering (described in Section 3 above) meant the policy was correcting against state that no longer reflected reality, amplifying the oscillation on every cycle.
Both issues had to be resolved together. Fixing the gains alone was insufficient while the policy was still consuming misordered state, and fixing CAN ordering alone was insufficient while the controller was underdamped.
5. Re-homing still matters
Even with a trained locomotion policy, real-robot alignment before execution remains important.
In practice:
- small asymmetries in the real robot can produce visible drift
- a careful home pose reduces bias before walking
- policy quality should not be judged independently of robot setup quality
This is particularly important for narrow-stance walking where small geometric biases can affect lateral balance.
6. Resulting deployment behavior
With the final stack, the legs locomotion policy achieved real-world behaviors including:
- forward walking
- backward walking
- lateral walking
- balance recovery under external pushes
The same underlying policy design was used across these cases, demonstrating that the transfer strategy was robust enough for more than a single scripted motion.
Sim-to-real locomotion rollouts showing forward walking, backward walking, lateral walking, and push recovery on real hardware.
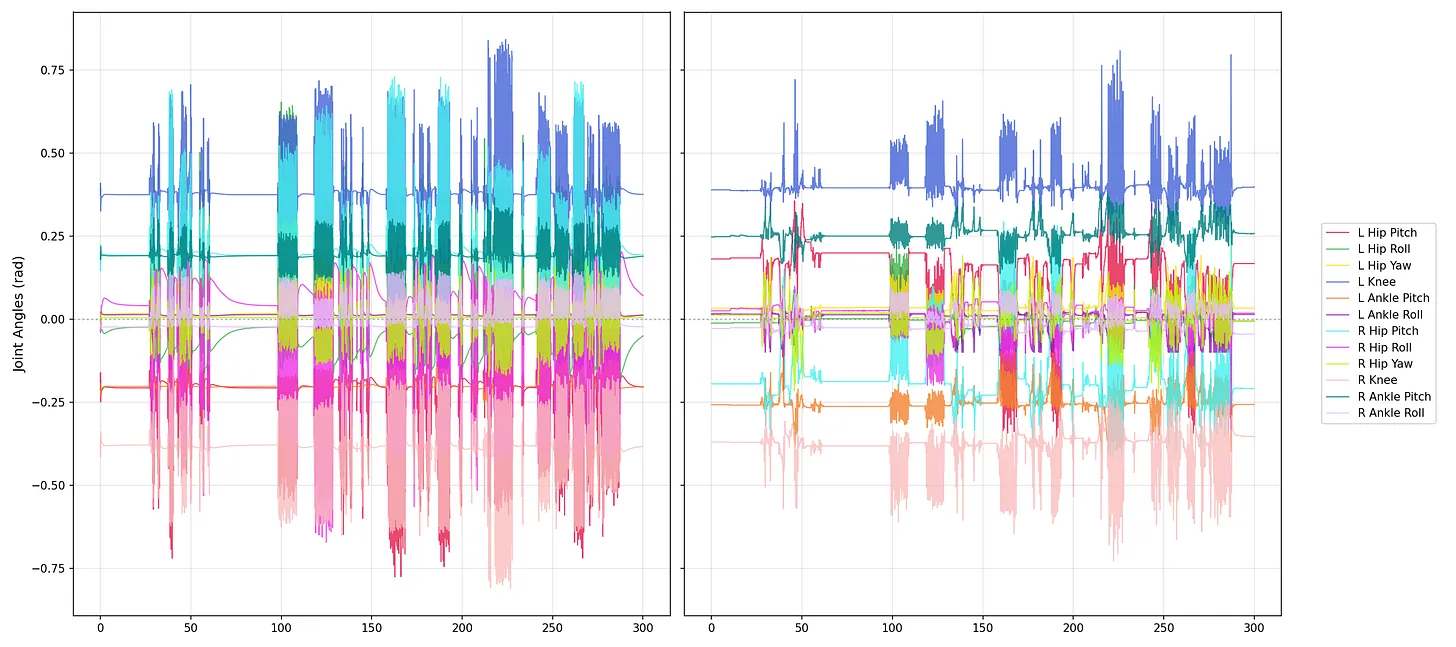
Figure: Joint trajectory comparison between real deployment and simulation. This comparison is included to show that sim2real success was evaluated not only by visual walking quality, but also by whether the commanded and observed motion patterns remained consistent across both domains.
7. Carryover to the full-body stack
The legs-only deployment work establishes the main ingredients that should carry into the full-body controller:
- the same leg actuator architecture
- the same staggered observation-delay philosophy
- the same privileged toe and contact information for training
- the same targeted randomization strategy
The full-body system introduces more joints and more coordination demands, but the sim2real foundation remains the same.
How is this guide?